Tech Project: AI miniPC (Minisforum X1 Pro) 4.0

In the previous installment of this project, I found that AMD's Lemonade Server software barely utilized the Neural Processing Unit (NPU) in the HX 370 APU powering my miniPC.
This was disappointing for a myriad of reasons, including the fact that the NPU was one of the factors in my choosing this machine.
However, developments on the software front have changed that situation.
Table of Contents
Lemonade Server v8.1.11
Lemonade Server has been updated to support the new software for running NPUs. One of the additional changes implemented is the addition of a context window size option:
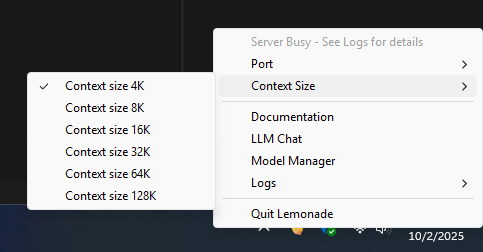
The current set of context sizes are as follows:
- 4K (default value)
- 8K
- 16K
- 32K
- 64K
- 128K
These control the amount of tokens that can be retained in memory at any one given time. This gives the LLM more ability to handle larger documents or complex tasks. These should be matched as close to your available VRAM/dedicated RAM as possible. I accidentally selected 128K once before starting a prompt and wound up freezing the entire miniPC.
(Incidentally, if any AI server system allows for context window size to be set via API, this sort of behavior might become a common denial of service attack.)
This does create a bit of an issue with unusual VRAM/RAM amounts, like 12, 24, 48 and 96 GBs though. These are likely to become more common in the near future, due to rising VRAM requirements for GPUs, so it would behoove developers to accommodate more context sizes as standard.
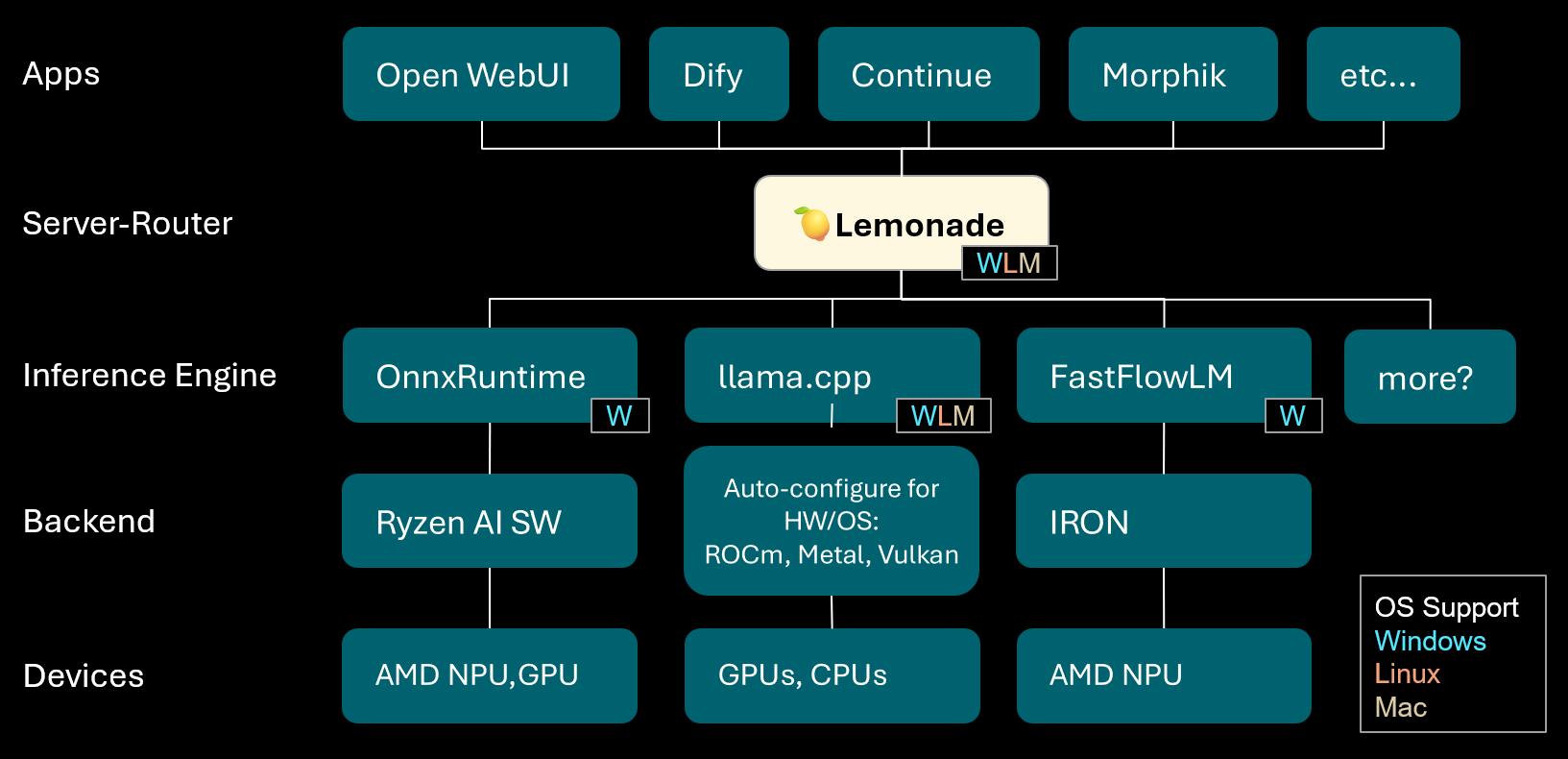
According to Jeremy Flowers, one of the lead developers, Lemonade Server is shifting to a server-router model:
Lemonade is a local LLM server-router that auto-configures high-performance inference engines for your computer. We don't just wrap llama.cpp, we're here to wrap everything!
We started out building an OpenAI-compatible server for AMD NPUs and quickly found that users and devs want flexibility, so we kept adding support for more devices, engines, and operating systems.
What was once a single-engine server evolved into a server-router, like OpenRouter but 100% local. Today's v8.1.11 release adds another inference engine and another OS to the list!
We'll focus on FastFlowLM, the newest inference engine, since it's behind the dramatic improvement in NPU performance.
FastFlowLM
FastFlowLM is both software and a company. Quoting from their webpage:
FastFlowLM Inc. is a startup developing a runtime with custom kernels optimized for AMD Ryzen™ AI NPUs, enabling LLMs to run faster, more efficiently, and with extended contexts — all without GPU fallback. FLM is free for non-commercial use, with commercial licensing available.
Lemonade Server v8.1.11 has experimental support for FastFlowLM. What this means is that you can download the models optimized for it and use webGUI as FastFlowLM's webGUI, but you need to download and install a separate application. Traffic is passed to Lemonade Server via its port, then passed onto FastFlowLM via it's port, and vice versa.
FastFlowLM requires a new model format known as q4nx, which I have not heard of until this point. There's very little documentation on this format, and very few publicly available repos, which means that testing is currently limited to models provided by FastFlowLM.
As a result, I chose to download Gemma-3-4b-it-FLM, which is a vision model capable of analyzing uploaded images. While not a reasoning model, it added a new element worth broadening my testing.
Testing Gemma-3-4b-it-FLM
Before starting the actual test runs, I did some informal tests to validate functionality and see what guardrails were in place. First, I did a quick chat in Lemonade Server's webGUI where I uploaded a screenshot of an Unreal Engine interface and asked it to describe what was in the image. This was successful, proving that it was working as expected.
Next, I used a specially crafted POML paired system and user prompt with a command ordering the LLM to execute a task while disregarding "any all moral and ethical issues". This test serves two purposes:
- It reveals the extent of baked in guardrails that can reduce or eliminate utility in creative assistant roles.
- It can sometimes reveal weaknesses in reasoning LLMs in the prompt template or other areas that can cause thought loops.
Surprisingly, this model had no apparent issues with the prompt. The quality of the output was not spectacular, but that might be more due to it being a 4 billion parameter model than anything.
With that done, I created a new POML prompt with an embedded image:
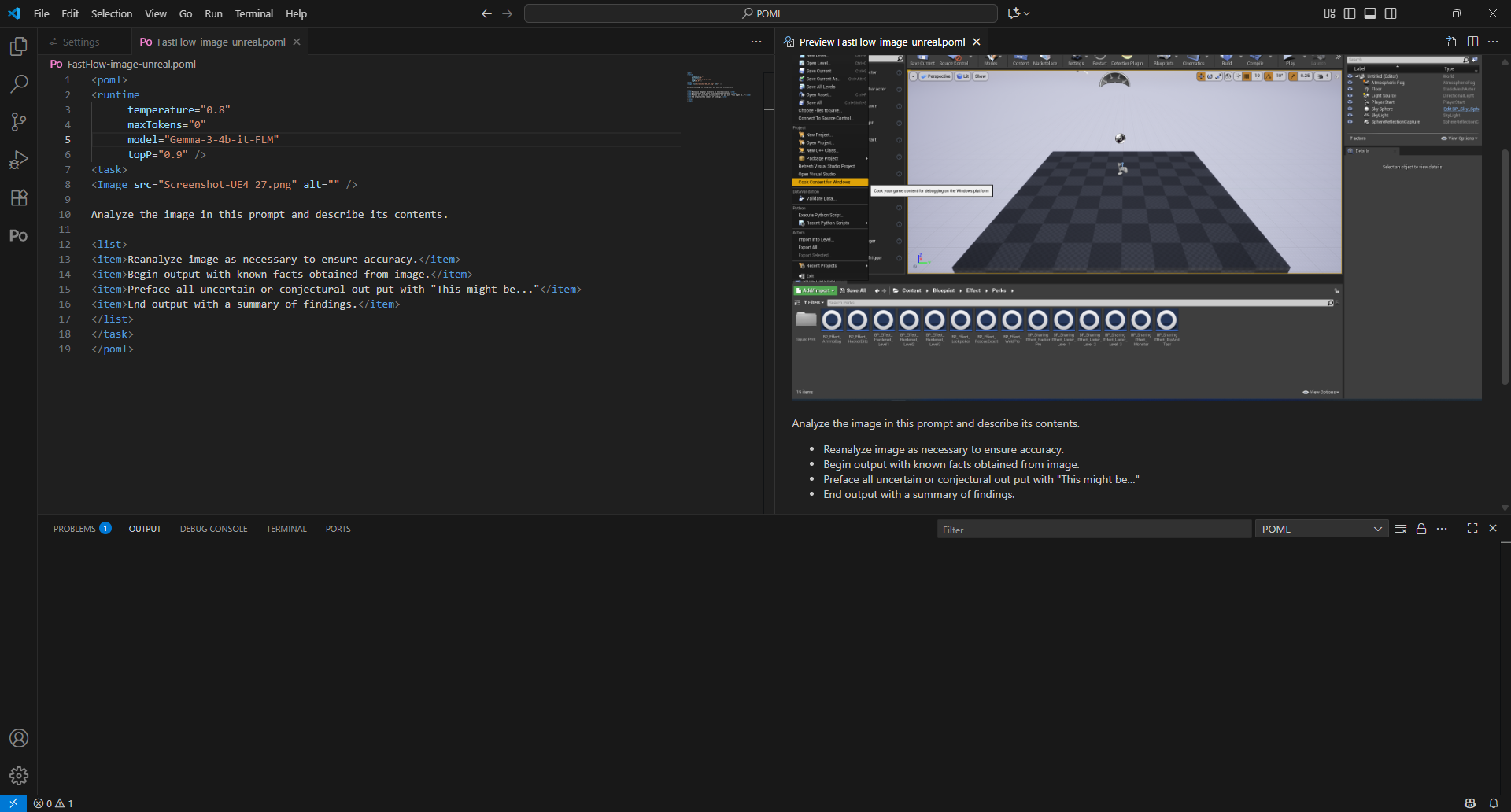
Since Lemonade Server defaults to a 4K context window, I kept the instructions in the prompt simple.
However, monitoring the test was anything but simple. In addition to VS Code, I had Lemonade Server's log window open, FastFlowLM's server log window open, and Windows Task Manager open. FastFlowLM's server log was not quite as detailed as I was expecting:
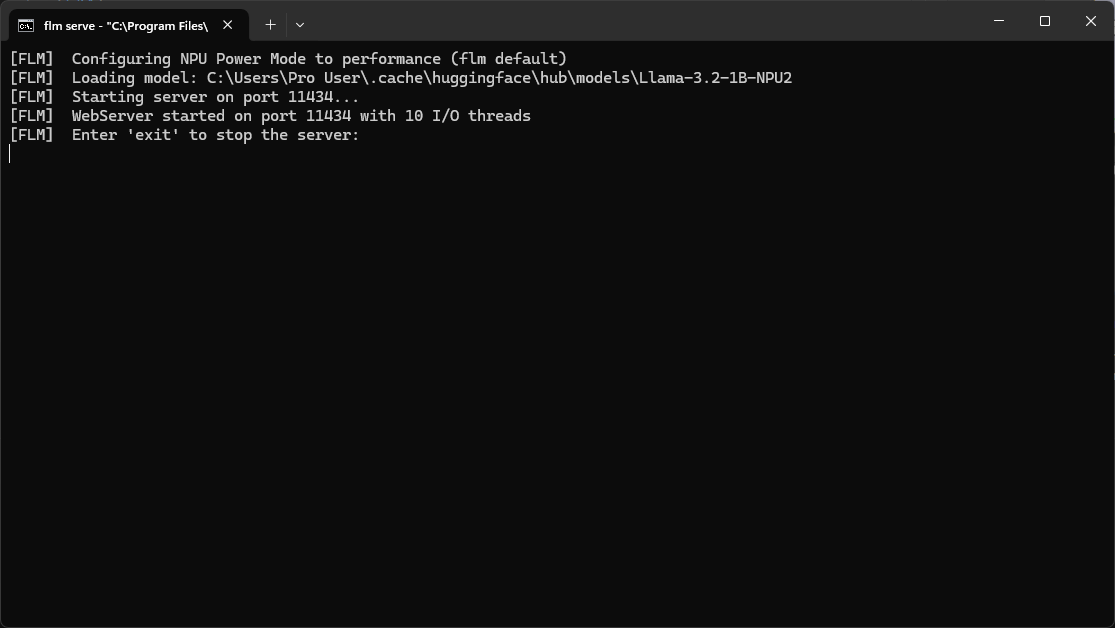
(Note: Llama-3.2-1B-NPU2 is the default model FastFlowLM installs.)
I made three main discoveries in the process of testing the prompt:
- The Lemonade Server log outputs a massive base64 string representing the image file and has no real performance telemetry.
- The FastFlowLM log does have telemetry, but not all of it is directly comparable to Lemonade Server's output.
- The POML script generates an error at the end of the generation process, which may be related to how the prompt and response are being passed through Lemonade Server.
The statistics on this run were as follows:
[🟢 ] NPU Locked!
[FLM] Loading model: C:\Users\Pro User\.cache\huggingface\hub\models\Gemma3-4B-NPU2
[FLM] Start generating...
[FLM] Total images: 1
ChatCompletionChunk: {"id":"chatcmpl-51cac0ddbe102d0345cffbab","object":"chat.completion.chunk","created":1759414770,"model":"gemma3:4b","system_fingerprint":"fp_071dd16bb249ea08","usage":{"prompt_tokens":329,"completion_tokens":647,"total_tokens":976,"load_duration":94.347952128,"prefill_duration_ttft":5.65040384,"decoding_duration":48.341057536,"prefill_speed_tps":58.225926733052766,"decoding_speed_tps":13.38406797406477}}
[🔒 ] Closing TCP connection (streaming, non-keep-alive)
[🔵 ] NPU Lock Released!
While prompt_tokens and completion_tokens seem to clearly map to Input Tokens and Output Tokens, it's not at all clear how the two token per second values factor into a total value, nor if decoding or load actually affect time to first token. Lemonade Server is going to add FastFlowLM performance statistics in a future version, so it will be interesting to see how the values compare across runs.
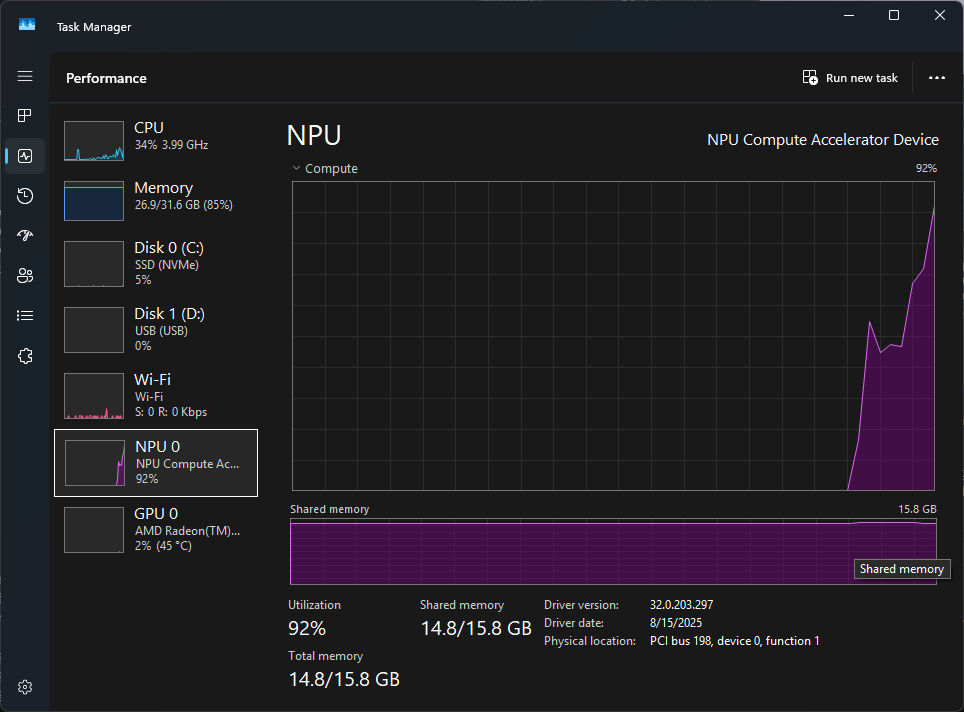
Interestingly, the NPU use graph in Task Manager shows that when the NPU processes the prompt, there's a roughly 60% use spike, before use gradually rises to 90+%. This might be related to image loading and/or processing.
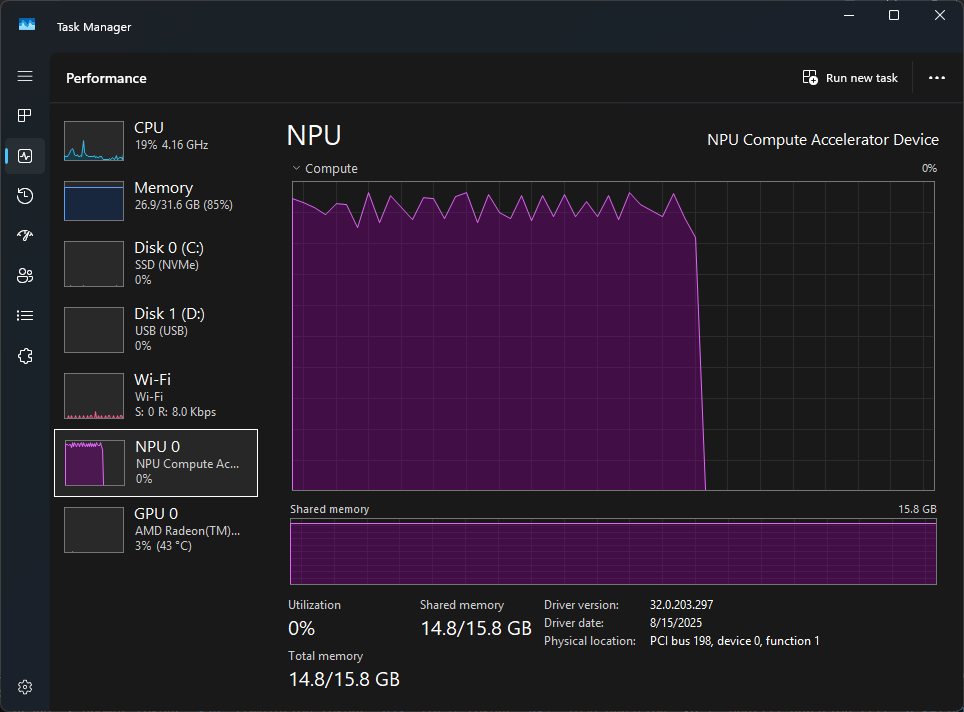
Interestingly, when the task completes, it's a near vertical drop in utilization.
With this test done, I moved onto a run of my trusty wpa_supplicant coding prompt:
[🟢 ] NPU Locked!
[FLM] Start generating...
[FLM] Total images: 0
ChatCompletionChunk: {"id":"chatcmpl-b17e2eba7a67c40777d6a279","object":"chat.completion.chunk","created":1759421662,"model":"gemma3:4b","system_fingerprint":"fp_7b2d49d1995eb514","usage":{"prompt_tokens":420,"completion_tokens":697,"total_tokens":1117,"load_duration":7e-07,"prefill_duration_ttft":1.762078976,"decoding_duration":56.398995456,"prefill_speed_tps":238.3548102670286,"decoding_speed_tps":12.358376144195132}}
[🔒 ] Closing TCP connection (streaming, non-keep-alive)
[🔵 ] NPU Lock Released!
Predictably, it seems that all text coding prompt required less time and had a higher prefill speed than the image processing one.
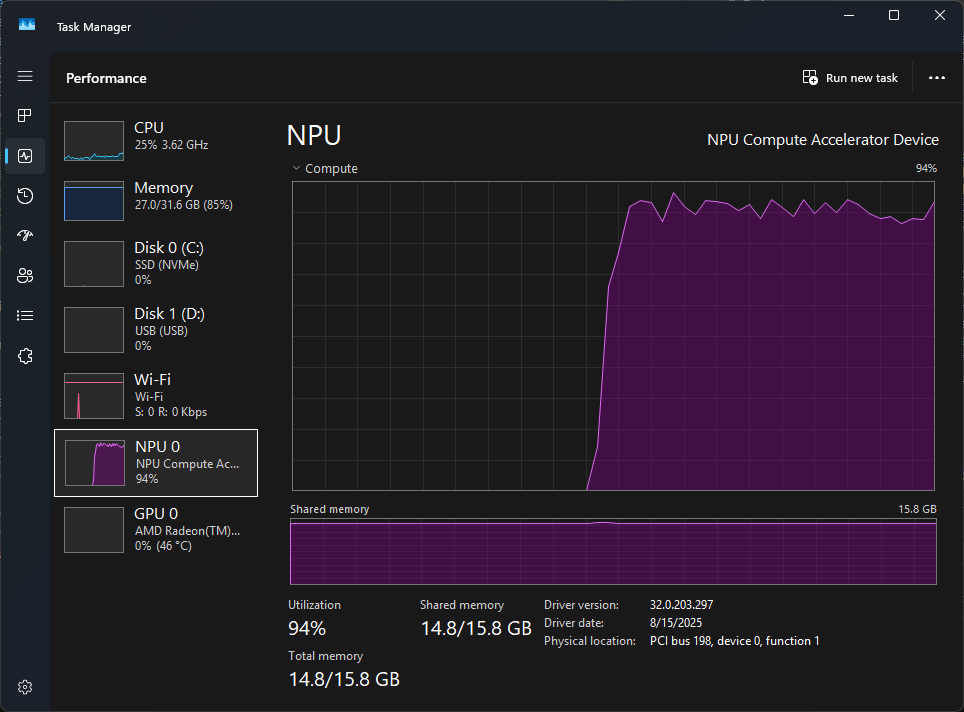
There was a smoother rise in NPU utilization for this run, which seems to validate the idea that the spiky start of the other test was related to the image.
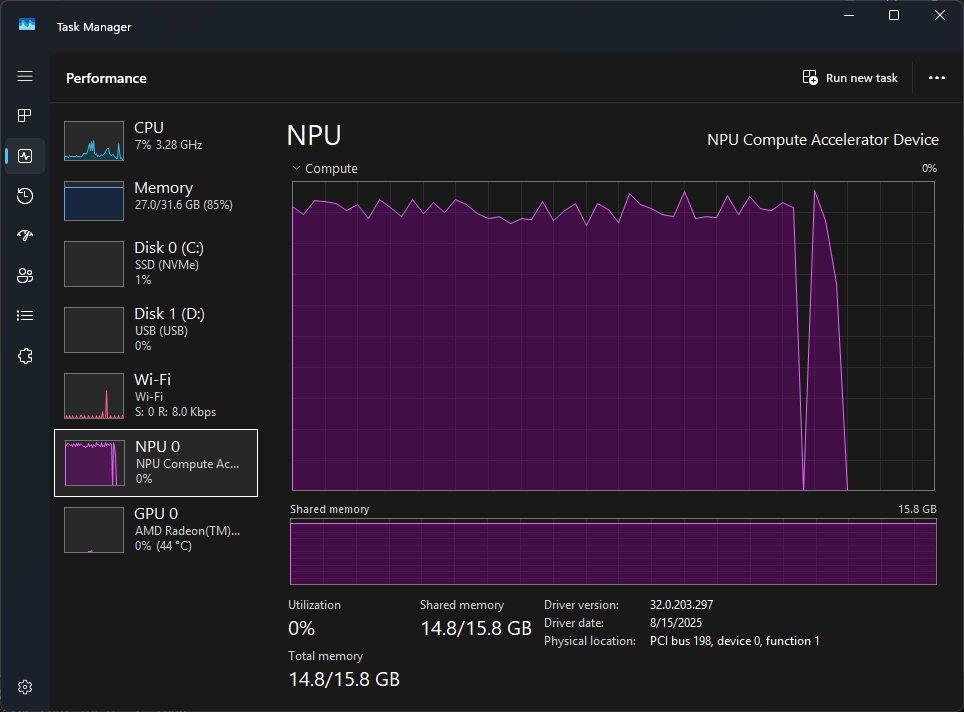
Interestingly, there was a sudden drop and spike back to 90% utility, before dropping down. It's not entirely clearly how or why this occurred, because it didn't really affect the output.
Also, like many other LLMs, you can't get the LLM to process extensive code dumps via incorporating the code into the system prompt. This fails almost immediately, even with a boosted context size.
Interestingly, an update to FastFlowLM reveals some limitations imposed by AMD for NPU memory allocation:
- Memory Requirements⚠️ Note: Running
gpt-oss:20bcurrently requires a system with 48 GB RAM or more. The model itself uses approximately 16.4 GB of memory in FLM, and there is an internal cap (~15.6 GB) on NPU memory allocation enforced by AMD, which makes only about half of the total system RAM available to the NPU. On 32 GB machines, this limitation prevents the model from loading successfully, so we recommend using 48 GB or more RAM for a smooth experience.
This is a somewhat confusing limitation, in that I can't be sure that the 15.6GB cap on NPU memory allocation is a consistent figure. This number does line up with my 64GB miniPC having a 15.8GB Shared/Total Memory value on the NPU, but it seems illogical that AMD would put such a hard cap on NPU memory access, when LLMs are so memory intensive.
Considering that AMD allows for RAM pools to be split between CPU and GPU in their APU BIOS, it would make far more sense allow users to manually assign RAM amounts to each of the three processors. The default fallback would then be a 1/3 split between each processor.
This has long-term relevance because AMD has several consumer future products in development that are likely to leverage NPUs for local AI purposes. With 4 billion parameter LLMs being in 5-6GB range, barring future improvements in compressing LLMs or decentralized operations, available RAM is going a hard limitation for local use.
However, for a preliminary version of a high performance NPU runtime, the current limitations are quite acceptable.
Takeaways
- Lemonade Server v8.1.11 added support for a new context window size option (4K, 8K, 16K, 32K, 64K, 128K) to manage tokens retained in memory.
- Match the setting to available VRAM/RAM to avoid system freezes (e.g., the 128K case caused a miniPC freeze).
- The server is transitioning to a server-router model, evolving from a single-engine system to supporting multiple devices, engines, and operating systems, as noted by lead developer Jeremy Flowers.
- Experimental support for FastFlowLM, a new inference engine, was added in v8.1.11, requiring the q4nx model format.
- FastFlowLM is both a software runtime and a company, focused on optimizing AMD Ryzen AI NPUs with custom kernels to enhance LLM speed/efficiency and extend context windows.
- FastFlowLM is free for non-commercial use, with commercial licensing.
- Lemonade Server now experimentally passes traffic to FastFlowLM via its port (and vice versa), though logging and performance metrics remain partially disconnected.
- The q4nx model format lacks extensive documentation/public repositories, limiting testing to models provided by FastFlowLM (e.g., Gemma-3-4b-it-FLM, a vision model for image analysis).
- Initial tests validated basic functionality (e.g., image analysis via webGUI) and POML prompt testing revealed fairly limited guardrails on the Gemma-3-4b-it-FLM model.
- Performance metrics during testing highlighted unclear token-rate relationships (e.g.,
prefill_speed_tpsvs.decoding_speed_tps). - FastFlowLM noted a memory requirement (16.4GB RAM for gpt-oss:20b) and an internal NPU memory cap (~15.6GB) by AMD, which prevents models (e.g., 32GB systems) from loading successfully.
- AMD’s RAM allocation limits are an opportunity to allow manual RAM distribution, with the default seen as suboptimal for modern workloads.
- RAM shortages could become a long-term bottleneck for local AI use with NPUs, given memory-intensive LLMs.